Kubernetes CronJob 完全指南
Linux Crontab 在过去作为执行定时任务的服务被广泛使用至今,但因其缺乏弹性,也出现了一些分布式的定时任务解决方案,比如 vipshop/Saturn、ihaolin/antares,那么在云原生时代,Kubernetes 作为最受欢迎的容器编排系统,它所提供的 CronJob 类型的工作负载,如何满足我们的需求,以及使用上会有哪些需要注意的地方,包括官方文档中没有讲述的细节,笔者将在这篇文章进行介绍。
Linux Crontab 相信很多人都熟悉,通过 crontab -u nobody -l 我们可以查看指定用户的定时任务,如果需要修改定时任务,则执行 crontab -u nobody -e,通过修改文件的方式配置定时任务,文件格式为:
# For details see man 4 crontabs
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executed
具体的调度执行是由 crond.service 负责。
Linux Crontab 的局限性:
- 单点故障
- 难以扩缩容,资源利用率不高
- 任务之间资源不隔离
- 不支持任务的并发执行与失败重试,需要业务自行实现
Kubernetes CronJob 支持的特性:
- 复用 Pod 的能力:调度、资源限制和隔离、容器失败重启
- 任务并发行执行,失败自动重试
- 保留成功/失败的任务执行记录
- 设置任务最大执行时间
- 方便地对任务运行状态进行监控
Kubernets CronJob 工作原理:
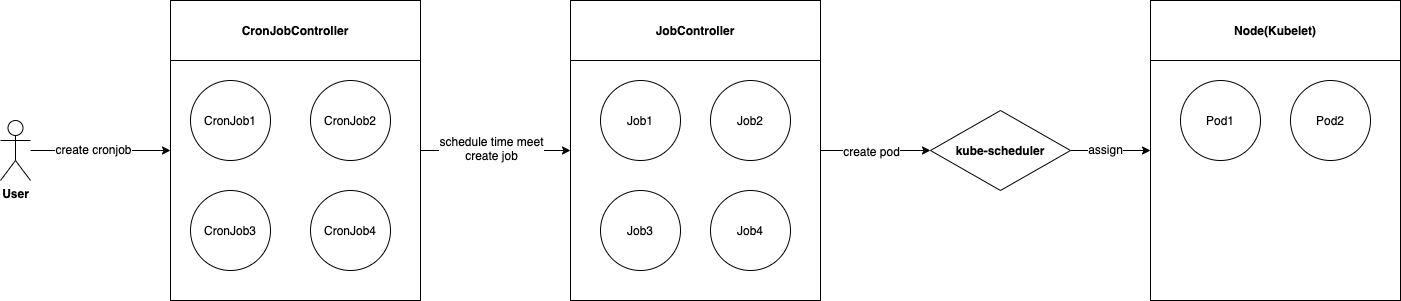
- 用户创建 CronJob 类型的资源
- CronJobController 每隔 10s 串行遍历所有的 CronJob 资源,判断是否有需要调度的 CronJob,如果有且条件允许,创建对应的 Job 资源
- JobController 监听到有 Job 被创建,则根据 Job 创建对应的 Pod 资源
- kube-scheduler 负责将 Pod 调度到可运行的节点上
- Kubelet 负责在节点上创建 Pod 运行环境,启动容器
CronJob 资源配置字段详解:
- concurrencyPolicy:当上一个调度时间点创建的 Job 还在执行时,当前调度时间点的调度策略,CronJobController 提供了三种类型的策略
- Allow:在调度时间点时始终进行调度(默认值)
- Forbid:不调度
- Replace:删除对应的所有活跃的 Job,再创建新的 Job
- failedJobsHistoryLimit:保留最近多少个失败的 Job,默认值 1
- successfulJobsHistoryLimit:保留最近多少个成功的 Job,默认值 3
- schedule:调度时间格式,参考 https://en.wikipedia.org/wiki/Cron
- startingDeadlineSeconds:影响到 CronJob 在其调度时间点上能否进行调度,见下文详解
- suspend:是否挂起
- true:不再调度新的 Job
- false:正常执行调度(默认值)
- jobTemplate:Job 模板,下文讲解
CronJob startingDeadlineSeconds 详解 如图:

- CreationTimestamp:CronJob 创建时间点
- LastScheduleTime:CronJob 最近一次的调度时间点
- current checkpoint:CronJobController 当前检查时间点
每当到达 current checkpoint 时,CronJobController 会统计过去一段时间区间内,miss 的可调度时间点个数如果超过 100 个,则不会再进行调度,从 CronJob 的事件中可以看到 FailedNeedsStart 的警告事件。这个时间区间的算法为:
earliestTime = LastScheduleTime != nil ? LastScheduleTime : CreationTimestamp
if StartingDeadlineSeconds != nil {
schedulingDeadline = now - StartingDeadlineSeconds
earliestTime = schedulingDeadline > earliestTime ? schedulingDeadline : earliestTime;
}
// 计算 [earliestTime, now] 这个时间区间内,miss 的可调度时间点
考虑这种场景:不设置 StartingDeadlineSeconds,然后把 CronJob suspend 很长时间之后 unsuspend,就有可能出现 miss 的可调度时间点个数超过 100 个,导致无法调度,那么为了解决这个问题,就需要设置 StartingDeadlineSeconds,确保 <= 100 * 调度周期。比如每分钟调度一次,那么 StartingDeadlineSeconds 需要设置为 <= 100 分钟。
那么 StartingDeadlineSeconds 直接设置为 0 是否可以呢?不行,因为 CronJobController 还会作如下判断:
if scheduledTime + StartingDeadlineSeconds < now {
// 不调度,记录 MissSchedule 的警告时间。
}
- scheduledTime:miss 的可调度时间点最新的一个,肯定是 <= now 的
这个判断就比较符合 StartingDeadlineSeconds 名称的语义了,如果在最新的可调度时间点之后多少秒内没有调度,则不调度。 所以建议 StartingDeadlineSeconds 最小可以设置为 60s。
CronJob jobTemplate 资源配置字段详解:
- activeDeadlineSeconds:默认值 nil,指定 Job 活跃时间,从 Job 被 JobController 发现的时间点开始计算,如果 Job 活跃时间超过 activeDeadlineSeconds,则 Job 以失败状态结束,并且会删除掉所有活跃的 Pod,记录 DeadlineExceeded 警告事件
- backoffLimit:默认值 6,意思是控制失败重试的次数(但并不等于业务代码执行时实际失败重试的次数),如果超过 backoffLimit,则 Job 以失败状态结束,记录 BackoffLimitExceeded 事件。有如下两种计算方式:
- 如果 template.spec.restartPolicy = OnFailure,那么累计所有处于 PodRunning/PodPending 状态的 Pod 的 Containers 和 InitContainers 的重启次数
- 如果 template.spec.restartPolicy = Never,那么计算 Job 被重新入队的次数(当同步时有新的 Pod 进入 PodFailed 状态,或者同步时遇到错误,会把 Job 重新入队),如果有 Pod 成功结束了,重新入队的次数会被重置
- completions:多少个 Pod 成功结束了(进入 PodSucceeded 状态)认为 Job 成功执行完了
- 当值为 nil 时,任何一个 Pod 成功结束,则 Job 成功执行完
- 当值为 0 时,将不会派生出 Pod 执行
- 默认值 nil,但是:
- 如果 completions = nil && parallelism = nil,那么 completions = 1
- manualSelector:bool 类型,默认值 false,是否设置 pod labels 和 selector 字段
- JobController 会自动为 Pod 生成唯一的 labels,并设置 job.spec.selector,使得 Job 关联到其创建的 Pod
- 建议值 false
- selector:manualSelector = true 时,该字段才能使用,设置关联 Pod 的 labels
- 建议不要设置,由 JobController 自动生成
- parallelism:默认值 1,控制并行度,即一个 Job 可以派生出多少个 Pod 并行执行,实际并行度受 completions 字段值限制
- 当 completions 字段值为 nil 时,并行度为 parallelism
- 当 completions 字段值 >= 1 时,并行度为 min(completions - successful, parallelism)
- template:Pod 模板
- restartPolicy:只允许为 Never 或 OnFailure
- 不允许为 Always,因为 Pod 无法结束
- 注意!当设置为 OnFailure,如果 Job 失败结束了,Pod 都会被删除,就无法查看失败 Pod 的现场了,因为 restartPolicy=OnFailure 的 Pod 会一直处于 PodRunning/PodPending 活跃状态,而 Job 失败结束的时候会删除掉所有活跃状态的 Pod
- restartPolicy:只允许为 Never 或 OnFailure
- ttlSecondsAfterFinished:设置成功或失败结束的 Job 的存在时间,达到指定时间,则会被自动删除,需要在 kube-apiserver 和 kube-controller-manager 上开启特性门控 TTLAfterFinished
- 当值为 nil 时,不自动删除(默认值)
- 当值为 0 时,立即删除
- 当值 >0 时,达到指定时间删除
并行度场景分析
下面讨论不同并行度需求场景下,completions 和 parallelism 的设置。
1、任务只需成功执行一次,建议设置 parallelism = 1,completions = 1
也可以都不设置,那么会被设置为默认值 parallelism = 1,completions = 1。 当然也可以设置 parallelism > 1,任何一个 Pod 成功结束都会使 Job 成功结束。
2、任务需要并行执行,并且成功结束的 Pod 达到指定个数才算成功结束,建议设置 parallelism = n(1<n<=m),completions = m(m>0)
3、任务不能并行执行,但成功结束的 Pod 需要达到指定个数,建议设置 parallelism = 1,completions = m(m>0)
任务监控
1、可通过查看 Pod 的监控数据,了解任务资源消耗、执行时间 2、基于 kubernetes 的事件进行告警
Job 的警告事件列表:
| REASON | MESSAGE | 说明 |
|---|---|---|
| BackoffLimitExceeded | Job has reached the specified backoff limit | 任务达到最大重试次数 backoffLimit |
| DeadlineExceeded | Job was active longer than specified deadline | 任务活跃时间超过了activeDeadlineSeconds |
| TooManyActivePods | Too many active pods running after completion count reached | 成功结束的 Pod 个数已经达到了 completions,但是还有活跃的 Pod,不符合调度预期(JobController 调度逻辑存在 Bug 或者设置了 manualSelector 和 selector,但没设置好) |
| TooManySucceededPods | Too many succeeded pods running after completion count reached | 成功结束的 Pod 个数超过了 completions,不符合调度预期(JobController 调度逻辑存在 Bug 或者设置了 manualSelector 和 selector,但没设置好) |
CronJob 的警告事件列表:
| REASON | MESSAGE | 说明 |
|---|---|---|
| UnexpectedJob | Saw a job that the controller did not create or forgot: %s | 发现一个活跃的 Job 不在 CronJob.Status.Active 列表中(可能是 CronJobController 在创建完 Job 之后 crash 了,还未来得及更新 .Status.Active) |
| MissingJob | Active job went missing: %v | CronJob.Status.Active 列表中存在找不到的 Job(可能被非预期的删除了) |
| FailedNeedsStart | Cannot determine if job needs to be started: %v | miss 的可调度时间点个数如果超过 100 个 |
| MissSchedule | Missed scheduled time to start a job: %s | StartingDeadlineSeconds 可能设置的太小了 |
| FailedGet | Get job: %v | 访问 kube-apiserver 失败了 |
| FailedCreate | Error creating job: %v | 访问 kube-apiserver 失败了 |
| FailedDelete | Deleted job: %v | 访问 kube-apiserver 失败了 |
CronJob 任务执行完成事件
| REASON | MESSAGE | 说明 |
|---|---|---|
| SawCompletedJob | Saw completed job: %s, status: %v | Job 结束的事件,包括成功或失败,需要通过 status 判断,Complete 表示成功,Failed 表示失败 |
3、基于 kube-controller-manager 的日志监控
如果 CronJobController 和 JobController 遇到访问 kube-apiserver 失败或者非预期的调度结果,会记录错误日志。
期望可能的改进点
1、CronJob 支持直接触发调度
当需要让 CronJob 立即执行一次调度时,目前都是得通过修改 schedule 配置实现,如果可以通过设置 Annotation 来触发调度就方便了。
2、Job 支持设置当超过最大活跃时间时,进行告警,而不是直接失败结束
这个笔者通过自定义的控制器,在 Annotation 上实现过。
Job 失败结束,统计状态不准确问题
通过 kubectl describe job 可以看到 Job 派生出来的 Pod 的执行状态:Pods Statuses: 0 Running / 1 Succeeded / 0 Failed,这个状态在 Job 如果是失败结束的情况下,是有可能统计不准确的,并且 Job 会出现多次进入失败状态。详情可看下 ISSUE:Job Controller: job.Status.Failed is incorrect in some cases。不过这个问题对实际业务应该没什么影响。
Crontab 迁移到 Kubernetes CronJob 需要注意的点
- Kubernetes Pod 会根据 Container 的退出状态码是否为 0,来判断是否成功结束了,所以业务代码实现上在失败的情况,退出码需要是非 0 的。
- 业务代码实现上最好能做到失败重试不影响业务,否则就需要把 Job.backoffLimit 设置为 0