golang goroutine 的创建、调度和释放
参考文章:
本文作为笔者学习 Golang 调度器实现的总结,笔者带着如下几个问题,研究 go1.13.1 源码。
- goroutine 是如何创建、调度、退出的?
- 调度器是如何对 goroutine 进行上下文切换的?
- 抢占式调度是怎么做的?
- go 启动的时候会创建多少个 M,M 的数量在何时会增加?
- 当 goroutine 阻塞时,关联的 P、M 会怎样?
goroutine 的创建
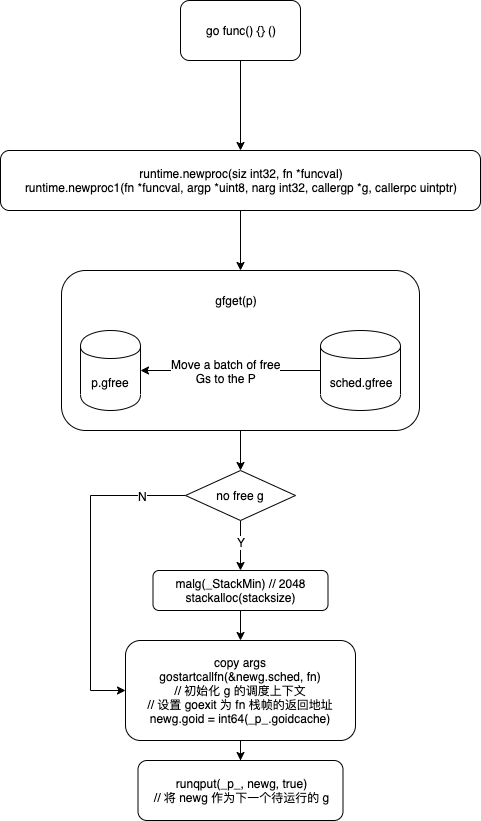
通过 go 关键字我们可以创建 goroutine,对应的底层是调用是runtime.newproc。
// Create a new g running fn with siz bytes of arguments.
// Put it on the queue of g's waiting to run.
// The compiler turns a go statement into a call to this.
// Cannot split the stack because it assumes that the arguments
// are available sequentially after &fn; they would not be
// copied if a stack split occurred.
//go:nosplit
func newproc(siz int32, fn *funcval) {
// size 参数大小
// fn 函数指针
argp := add(unsafe.Pointer(&fn), sys.PtrSize) // fn 参数指针
gp := getg() // 获取当前的 g
pc := getcallerpc() // go func () {} () 之后的下一条指令
systemstack(func() { // 切换到 g0 调用 newproc1
newproc1(fn, (*uint8)(argp), siz, gp, pc)
})
}
// Create a new g running fn with narg bytes of arguments starting
// at argp. callerpc is the address of the go statement that created
// this. The new g is put on the queue of g's waiting to run.
func newproc1(fn *funcval, argp *uint8, narg int32, callergp *g, callerpc uintptr) {
_g_ := getg() // 获取 g0
if fn == nil {
_g_.m.throwing = -1 // do not dump full stacks
throw("go of nil func value")
}
// _g_.m.locks++ 禁止抢占
acquirem() // disable preemption because it can be holding p in a local var
siz := narg
siz = (siz + 7) &^ 7 // 将 siz 调整为 8 的倍数
// We could allocate a larger initial stack if necessary.
// Not worth it: this is almost always an error.
// 4*sizeof(uintreg): extra space added below
// sizeof(uintreg): caller's LR (arm) or return address (x86, in gostartcall).
if siz >= _StackMin-4*sys.RegSize-sys.RegSize {
throw("newproc: function arguments too large for new goroutine")
}
_p_ := _g_.m.p.ptr() // 获取当前 P
newg := gfget(_p_) // 从 p.gFree 获取空闲的 g,如果 p.gFree 为空,则从全局的 sched.gFree 中搬运一部分到 p.gFree
if newg == nil { // 如果还是获取不到 g 的话,则申请分配一个 g
newg = malg(_StackMin) // 最小堆栈 2k
casgstatus(newg, _Gidle, _Gdead) // 确保 new 的状态由 _Gidle 转为 _Gdead
// 添加到全局g数组中
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}
if newg.stack.hi == 0 {
throw("newproc1: newg missing stack")
}
if readgstatus(newg) != _Gdead {
throw("newproc1: new g is not Gdead")
}
totalSize := 4*sys.RegSize + uintptr(siz) + sys.MinFrameSize // extra space in case of reads slightly beyond frame
totalSize += -totalSize & (sys.SpAlign - 1) // align to spAlign
sp := newg.stack.hi - totalSize
spArg := sp
if usesLR {
// 特定系统架构下需要的处理
// caller's LR
*(*uintptr)(unsafe.Pointer(sp)) = 0
prepGoExitFrame(sp)
spArg += sys.MinFrameSize
}
if narg > 0 {
// 复制参数
memmove(unsafe.Pointer(spArg), unsafe.Pointer(argp), uintptr(narg))
// 跟 gc 相关,先跳过
// This is a stack-to-stack copy. If write barriers
// are enabled and the source stack is grey (the
// destination is always black), then perform a
// barrier copy. We do this *after* the memmove
// because the destination stack may have garbage on
// it.
if writeBarrier.needed && !_g_.m.curg.gcscandone {
f := findfunc(fn.fn)
stkmap := (*stackmap)(funcdata(f, _FUNCDATA_ArgsPointerMaps))
if stkmap.nbit > 0 {
// We're in the prologue, so it's always stack map index 0.
bv := stackmapdata(stkmap, 0)
bulkBarrierBitmap(spArg, spArg, uintptr(bv.n)*sys.PtrSize, 0, bv.bytedata)
}
}
}
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
// 调度需要的信息
newg.sched.sp = sp
newg.stktopsp = sp
newg.sched.pc = funcPC(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg))
// 对 newg.sched 做调整
gostartcallfn(&newg.sched, fn)
newg.gopc = callerpc
newg.ancestors = saveAncestors(callergp) // debug.tracebackancestors 调试使用
newg.startpc = fn.fn
if _g_.m.curg != nil {
newg.labels = _g_.m.curg.labels
}
if isSystemGoroutine(newg, false) { // 判断是否为 runtime 的 goroutine
atomic.Xadd(&sched.ngsys, +1)
}
newg.gcscanvalid = false
casgstatus(newg, _Gdead, _Grunnable)
if _p_.goidcache == _p_.goidcacheend {
// Sched.goidgen is the last allocated id,
// this batch must be [sched.goidgen+1, sched.goidgen+GoidCacheBatch].
// At startup sched.goidgen=0, so main goroutine receives goid=1.
// 从全局的 sched 批量申请 goroutine id
_p_.goidcache = atomic.Xadd64(&sched.goidgen, _GoidCacheBatch)
_p_.goidcache -= _GoidCacheBatch - 1
_p_.goidcacheend = _p_.goidcache + _GoidCacheBatch
}
newg.goid = int64(_p_.goidcache) // 分配 goroutine id
_p_.goidcache++
if raceenabled {
newg.racectx = racegostart(callerpc)
}
if trace.enabled {
traceGoCreate(newg, newg.startpc)
}
// 将 newg 作为下一个待运行的 g
runqput(_p_, newg, true)
// 如果有其它空闲的 P,并且没有 M 处于自旋等待 P 或 G,以及当前 g 不是 main goroutine
if atomic.Load(&sched.npidle) != 0 && atomic.Load(&sched.nmspinning) == 0 && mainStarted {
wakep()
}
releasem(_g_.m)
}
func runqput(_p_ *p, gp *g, next bool) {
if randomizeScheduler && next && fastrand()%2 == 0 {
next = false
}
// 如果 next = true,将 gp 设置为下一个运行的 goroutine
if next {
retryNext:
// _p_.runnext 会在 runqgrab 中被并发访问,所以需要采用原子操作
oldnext := _p_.runnext
if !_p_.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) {
goto retryNext
}
if oldnext == 0 {
return
}
// Kick the old runnext out to the regular run queue.
gp = oldnext.ptr()
}
retry:
// 添加到本地无锁循环队列
h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with consumers
t := _p_.runqtail
if t-h < uint32(len(_p_.runq)) {
_p_.runq[t%uint32(len(_p_.runq))].set(gp)
atomic.StoreRel(&_p_.runqtail, t+1) // store-release, makes the item available for consumption
return
}
// 如果本地队列满了,则将本地队列半数的 goroutine 转移到全局 shced.runq
if runqputslow(_p_, gp, h, t) {
return
}
// the queue is not full, now the put above must succeed
goto retry
}
goroutine 创建图示:
goroutine 调度执行
通过搜索调用func runqget(_p_ *p) (gp *g, inheritTime bool)的地方,找到了调度的入口是runtime.schedule(),而调用runtime.schedule()的地方有:
- func exitsyscall0(gp *g):当 g 结束系统调用时,发现没有空闲的 p 可用
- func goexit0(gp *g):g 结束了
- func goschedImpl(gp *g):g 抢占、gc 开始和结束的时候
- func mstart1():程序启动的时候
- func park_m(gp *g):g 阻塞的时候
系统调用
参考文章:cch123/golang-notes/syscall
go 中用户代码进入系统调用的入口在src/syscall/syscall_linux.go,该文件中定义了三种类型的系统调用:
- 阻塞的:注释为 //sys 开头(grep ‘//sys\t’ syscall_linux.go),通过
Syscall6或Syscall执行系统调用 - 非阻塞的:注释为 //sysnb 开头(grep ‘//sysnb\t’ syscall_linux.go),通过
RawSyscall6和RawSyscall执行系统调用 - 封装的:例如 Rename -> RenameAt,主要是对输入参数做一些简化
Syscall与RawSyscall的区别在于,Syscall会在系统调用执行前(runtime.entersyscall)和执行后(runtime.exitsyscall)通知 runtime。
runtime.entersyscall会导致 p 与 m 分离,释放 p,使得 p 可以被 sysmon 系统监控线程抢走,并被其他 m 使用:
// Standard syscall entry used by the go syscall library and normal cgo calls.
//
// This is exported via linkname to assembly in the syscall package.
//
//go:nosplit
//go:linkname entersyscall
func entersyscall() {
reentersyscall(getcallerpc(), getcallersp())
}
func reentersyscall(pc, sp uintptr) {
_g_ := getg()
// Disable preemption because during this function g is in Gsyscall status,
// but can have inconsistent g->sched, do not let GC observe it.
_g_.m.locks++
// Entersyscall must not call any function that might split/grow the stack.
// (See details in comment above.)
// Catch calls that might, by replacing the stack guard with something that
// will trip any stack check and leaving a flag to tell newstack to die.
_g_.stackguard0 = stackPreempt
_g_.throwsplit = true
// Leave SP around for GC and traceback.
// 保存堆栈指针 sp 和程序计数器 pc 到 g.sched 中
save(pc, sp)
_g_.syscallsp = sp
_g_.syscallpc = pc
casgstatus(_g_, _Grunning, _Gsyscall)
if _g_.syscallsp < _g_.stack.lo || _g_.stack.hi < _g_.syscallsp {
systemstack(func() {
print("entersyscall inconsistent ", hex(_g_.syscallsp), " [", hex(_g_.stack.lo), ",", hex(_g_.stack.hi), "]\n")
throw("entersyscall")
})
}
if trace.enabled {
systemstack(traceGoSysCall)
// systemstack itself clobbers g.sched.{pc,sp} and we might
// need them later when the G is genuinely blocked in a
// syscall
// systemstack 会修改 g.sched,所以需要重新保存
save(pc, sp)
}
// 确保 sysmon 监控线程运行,因为它负责将因系统调用而长时间阻塞的 P 抢走,用于执行其它任务
if atomic.Load(&sched.sysmonwait) != 0 {
systemstack(entersyscall_sysmon)
save(pc, sp)
}
if _g_.m.p.ptr().runSafePointFn != 0 {
// runSafePointFn may stack split if run on this stack
systemstack(runSafePointFn)
save(pc, sp)
}
_g_.m.syscalltick = _g_.m.p.ptr().syscalltick
_g_.sysblocktraced = true
// 将 m 与 p 解除关联
_g_.m.mcache = nil
pp := _g_.m.p.ptr()
pp.m = 0
_g_.m.oldp.set(pp)
_g_.m.p = 0
atomic.Store(&pp.status, _Psyscall)
if sched.gcwaiting != 0 {
systemstack(entersyscall_gcwait)
save(pc, sp)
}
_g_.m.locks--
}
系统调用结束后执行runtime.exitsyscall:
func exitsyscall() {
_g_ := getg() // 获取当前 g
_g_.m.locks++ // see comment in entersyscall
if getcallersp() > _g_.syscallsp {
throw("exitsyscall: syscall frame is no longer valid")
}
_g_.waitsince = 0
oldp := _g_.m.oldp.ptr() // 获取进入系统调用前使用的 p
_g_.m.oldp = 0
if exitsyscallfast(oldp) {
if _g_.m.mcache == nil {
throw("lost mcache")
}
if trace.enabled {
if oldp != _g_.m.p.ptr() || _g_.m.syscalltick != _g_.m.p.ptr().syscalltick {
systemstack(traceGoStart)
}
}
// There's a cpu for us, so we can run.
_g_.m.p.ptr().syscalltick++
// We need to cas the status and scan before resuming...
casgstatus(_g_, _Gsyscall, _Grunning)
// Garbage collector isn't running (since we are),
// so okay to clear syscallsp.
_g_.syscallsp = 0
_g_.m.locks--
if _g_.preempt {
// restore the preemption request in case we've cleared it in newstack
_g_.stackguard0 = stackPreempt
} else {
// otherwise restore the real _StackGuard, we've spoiled it in entersyscall/entersyscallblock
_g_.stackguard0 = _g_.stack.lo + _StackGuard
}
_g_.throwsplit = false
if sched.disable.user && !schedEnabled(_g_) {
// Scheduling of this goroutine is disabled.
Gosched()
}
return
}
// 没找到可用的 P
_g_.sysexitticks = 0
if trace.enabled {
// Wait till traceGoSysBlock event is emitted.
// This ensures consistency of the trace (the goroutine is started after it is blocked).
for oldp != nil && oldp.syscalltick == _g_.m.syscalltick {
osyield()
}
// We can't trace syscall exit right now because we don't have a P.
// Tracing code can invoke write barriers that cannot run without a P.
// So instead we remember the syscall exit time and emit the event
// in execute when we have a P.
_g_.sysexitticks = cputicks()
}
_g_.m.locks--
// Call the scheduler.
mcall(exitsyscall0) // 移除当前 g 与 m 的关联,将当前 g 放到调度器的可执行队列中,并执行调度器的调度操作,即 runtime.schedule 函数
// g 被调度执行了
if _g_.m.mcache == nil {
throw("lost mcache")
}
// Scheduler returned, so we're allowed to run now.
// Delete the syscallsp information that we left for
// the garbage collector during the system call.
// Must wait until now because until gosched returns
// we don't know for sure that the garbage collector
// is not running.
_g_.syscallsp = 0
_g_.m.p.ptr().syscalltick++
_g_.throwsplit = false
}
func exitsyscallfast(oldp *p) bool {
_g_ := getg()
// 调度器停止调度
// Freezetheworld sets stopwait but does not retake P's.
if sched.stopwait == freezeStopWait {
return false
}
// oldp 是否还处于 _Psyscall 状态,如果是的话,直接拿来用
// Try to re-acquire the last P.
if oldp != nil && oldp.status == _Psyscall && atomic.Cas(&oldp.status, _Psyscall, _Pidle) {
// There's a cpu for us, so we can run.
wirep(oldp) // 将 p 与 m 进行关联
exitsyscallfast_reacquired()
return true
}
// 寻找其他空闲的 P
// Try to get any other idle P.
if sched.pidle != 0 {
var ok bool
systemstack(func() {
// 尝试从调度器的空闲 P 列表中获取
ok = exitsyscallfast_pidle()
if ok && trace.enabled {
if oldp != nil {
// Wait till traceGoSysBlock event is emitted.
// This ensures consistency of the trace (the goroutine is started after it is blocked).
for oldp.syscalltick == _g_.m.syscalltick {
osyield()
}
}
traceGoSysExit(0)
}
})
if ok {
return true
}
}
return false
}
调度循环
// One round of scheduler: find a runnable goroutine and execute it.
// Never returns.
func schedule() {
_g_ := getg()
if _g_.m.locks != 0 {
throw("schedule: holding locks")
}
if _g_.m.lockedg != 0 {
stoplockedm()
execute(_g_.m.lockedg.ptr(), false) // Never returns.
}
// We should not schedule away from a g that is executing a cgo call,
// since the cgo call is using the m's g0 stack.
if _g_.m.incgo {
throw("schedule: in cgo")
}
top:
if sched.gcwaiting != 0 {
gcstopm()
goto top
}
if _g_.m.p.ptr().runSafePointFn != 0 {
runSafePointFn()
}
var gp *g
var inheritTime bool
// Normal goroutines will check for need to wakeP in ready,
// but GCworkers and tracereaders will not, so the check must
// be done here instead.
tryWakeP := false
if trace.enabled || trace.shutdown {
gp = traceReader()
if gp != nil {
casgstatus(gp, _Gwaiting, _Grunnable)
traceGoUnpark(gp, 0)
tryWakeP = true
}
}
// gc mark 阶段,运行标记 goroutine:_p_.gcBgMarkWorker
if gp == nil && gcBlackenEnabled != 0 {
gp = gcController.findRunnableGCWorker(_g_.m.p.ptr())
tryWakeP = tryWakeP || gp != nil
}
// 确保全局等待队列中的 g 也能被调度
if gp == nil {
// Check the global runnable queue once in a while to ensure fairness.
// Otherwise two goroutines can completely occupy the local runqueue
// by constantly respawning each other.
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}
// 从 p 的本地队列中获取等待执行的 g
if gp == nil {
gp, inheritTime = runqget(_g_.m.p.ptr())
if gp != nil && _g_.m.spinning {
throw("schedule: spinning with local work")
}
}
if gp == nil {
// 尝试从其他 p 中偷取部分 g
// 从全局等待队列获取 g
// 从网络I/O等待队列中获取可执行的 g
gp, inheritTime = findrunnable() // blocks until work is available
}
// This thread is going to run a goroutine and is not spinning anymore,
// so if it was marked as spinning we need to reset it now and potentially
// start a new spinning M.
if _g_.m.spinning {
resetspinning()
}
if sched.disable.user && !schedEnabled(gp) {
// Scheduling of this goroutine is disabled. Put it on
// the list of pending runnable goroutines for when we
// re-enable user scheduling and look again.
lock(&sched.lock)
if schedEnabled(gp) {
// Something re-enabled scheduling while we
// were acquiring the lock.
unlock(&sched.lock)
} else {
sched.disable.runnable.pushBack(gp)
sched.disable.n++
unlock(&sched.lock)
goto top
}
}
// If about to schedule a not-normal goroutine (a GCworker or tracereader),
// wake a P if there is one.
if tryWakeP {
if atomic.Load(&sched.npidle) != 0 && atomic.Load(&sched.nmspinning) == 0 {
wakep()
}
}
if gp.lockedm != 0 {
// Hands off own p to the locked m,
// then blocks waiting for a new p.
startlockedm(gp)
goto top
}
execute(gp, inheritTime)
}
goroutine 抢占
从监控线程 sysmon 开始看:
// Always runs without a P, so write barriers are not allowed.
//
//go:nowritebarrierrec
func sysmon() {
lock(&sched.lock)
sched.nmsys++
checkdead() // 死锁检查
unlock(&sched.lock)
lasttrace := int64(0)
idle := 0 // how many cycles in succession we had not wokeup somebody
delay := uint32(0)
for {
if idle == 0 { // start with 20us sleep...
delay = 20
} else if idle > 50 { // start doubling the sleep after 1ms...
delay *= 2
}
if delay > 10*1000 { // up to 10ms
delay = 10 * 1000
}
usleep(delay)
// gc STW
// 所有 P 都空闲
if debug.schedtrace <= 0 && (sched.gcwaiting != 0 || atomic.Load(&sched.npidle) == uint32(gomaxprocs)) {
lock(&sched.lock)
if atomic.Load(&sched.gcwaiting) != 0 || atomic.Load(&sched.npidle) == uint32(gomaxprocs) {
// sysmon 进入休眠
atomic.Store(&sched.sysmonwait, 1)
unlock(&sched.lock)
// Make wake-up period small enough
// for the sampling to be correct.
maxsleep := forcegcperiod / 2
shouldRelax := true
if osRelaxMinNS > 0 {
next := timeSleepUntil()
now := nanotime()
if next-now < osRelaxMinNS {
shouldRelax = false
}
}
if shouldRelax {
osRelax(true)
}
notetsleep(&sched.sysmonnote, maxsleep)
if shouldRelax {
osRelax(false)
}
// sysmon 退出休眠
lock(&sched.lock)
atomic.Store(&sched.sysmonwait, 0)
noteclear(&sched.sysmonnote)
idle = 0
delay = 20
}
unlock(&sched.lock)
}
// trigger libc interceptors if needed
if *cgo_yield != nil {
asmcgocall(*cgo_yield, nil)
}
// poll network if not polled for more than 10ms
lastpoll := int64(atomic.Load64(&sched.lastpoll))
now := nanotime()
if netpollinited() && lastpoll != 0 && lastpoll+10*1000*1000 < now {
atomic.Cas64(&sched.lastpoll, uint64(lastpoll), uint64(now))
list := netpoll(false) // non-blocking - returns list of goroutines
if !list.empty() {
// Need to decrement number of idle locked M's
// (pretending that one more is running) before injectglist.
// Otherwise it can lead to the following situation:
// injectglist grabs all P's but before it starts M's to run the P's,
// another M returns from syscall, finishes running its G,
// observes that there is no work to do and no other running M's
// and reports deadlock.
incidlelocked(-1)
injectglist(&list)
incidlelocked(1)
}
}
// 抢夺因为 syscall 而长时间阻塞的 P
// 对长时间运行的 G 发起抢占
// retake P's blocked in syscalls
// and preempt long running G's
if retake(now) != 0 {
idle = 0
} else {
idle++
}
// check if we need to force a GC
if t := (gcTrigger{kind: gcTriggerTime, now: now}); t.test() && atomic.Load(&forcegc.idle) != 0 {
lock(&forcegc.lock)
forcegc.idle = 0
var list gList
list.push(forcegc.g)
injectglist(&list)
unlock(&forcegc.lock)
}
if debug.schedtrace > 0 && lasttrace+int64(debug.schedtrace)*1000000 <= now {
lasttrace = now
schedtrace(debug.scheddetail > 0)
}
}
}
// forcePreemptNS is the time slice given to a G before it is
// preempted.
const forcePreemptNS = 10 * 1000 * 1000 // 10ms
func retake(now int64) uint32 {
n := 0
// Prevent allp slice changes. This lock will be completely
// uncontended unless we're already stopping the world.
lock(&allpLock)
// We can't use a range loop over allp because we may
// temporarily drop the allpLock. Hence, we need to re-fetch
// allp each time around the loop.
for i := 0; i < len(allp); i++ {
_p_ := allp[i]
if _p_ == nil {
// This can happen if procresize has grown
// allp but not yet created new Ps.
continue
}
pd := &_p_.sysmontick
s := _p_.status
sysretake := false
if s == _Prunning || s == _Psyscall {
// Preempt G if it's running for too long.
// 如果 G 运行时间过长,则进行抢占
t := int64(_p_.schedtick)
// pd 是统计信息
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
} else if pd.schedwhen+forcePreemptNS <= now {
// 最近的一次调度,到现在已经超过 10 ms 了
preemptone(_p_)
// In case of syscall, preemptone() doesn't
// work, because there is no M wired to P.
sysretake = true
}
}
if s == _Psyscall {
// Retake P from syscall if it's there for more than 1 sysmon tick (at least 20us).
t := int64(_p_.syscalltick)
if !sysretake && int64(pd.syscalltick) != t {
pd.syscalltick = uint32(t)
pd.syscallwhen = now
continue
}
// On the one hand we don't want to retake Ps if there is no other work to do,
// but on the other hand we want to retake them eventually
// because they can prevent the sysmon thread from deep sleep.
// 当前 P 没有待运行的 G,且存在空闲的 M 或 P,且进入 syscall 状态还不到 10 ms
// 不抢夺
if runqempty(_p_) && atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) > 0 && pd.syscallwhen+10*1000*1000 > now {
continue
}
// Drop allpLock so we can take sched.lock.
unlock(&allpLock)
// Need to decrement number of idle locked M's
// (pretending that one more is running) before the CAS.
// Otherwise the M from which we retake can exit the syscall,
// increment nmidle and report deadlock.
// 抢夺 P
incidlelocked(-1)
if atomic.Cas(&_p_.status, s, _Pidle) {
if trace.enabled {
traceGoSysBlock(_p_)
traceProcStop(_p_)
}
n++
_p_.syscalltick++
handoffp(_p_)
}
incidlelocked(1)
lock(&allpLock)
}
}
unlock(&allpLock)
return uint32(n)
}
func preemptone(_p_ *p) bool {
mp := _p_.m.ptr()
// 如果 p 是与当前的 m 绑定的,不抢占
if mp == nil || mp == getg().m {
return false
}
gp := mp.curg
// 如果 m 正在执行 g0,不抢占
if gp == nil || gp == mp.g0 {
return false
}
// 抢占
gp.preempt = true
// Every call in a go routine checks for stack overflow by
// comparing the current stack pointer to gp->stackguard0.
// Setting gp->stackguard0 to StackPreempt folds
// preemption into the normal stack overflow check.
// 在栈扩容的时候进行抢占
gp.stackguard0 = stackPreempt
return true
}
实际抢占发生在:
- 栈扩容
runtime.newstack()的时候(当 g 被抢占时,g.stackguard0 = stackPreempt > sp) - GC 标记的时候(这里并没有看明白)
直到 go1.13.1 版本,尚未解决 for 循环中不存在函数调用的抢占问题(这个问题会导致 gc STW 等待时间过长)。如下代码运行后无法输出OK:
package main
import (
"runtime"
"time"
)
func main() {
runtime.GOMAXPROCS(1)
go func() {
for {
}
}()
time.Sleep(time.Millisecond)
println("OK")
}
为了解决这个问题,在 go1.14 版本中,通过向 M 发送抢占信号 SIGURG 来解决,操作系统会中断 M ,并执行信号处理函数。信号处理函数修改 M 的上下文,并恢复到 asyncPreempt 中执行,然后进入调度循环。具体可参考Go Under The Hood 抢占式调度/M 抢占。
goroutine 的退出
在 goroutine 创建的时候,调度的上下文 PC 被设置为 goexit 函数:
newg.sched.sp = sp
newg.stktopsp = sp
newg.sched.pc = funcPC(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
newg.gopc = callerpc
newg.ancestors = saveAncestors(callergp)
newg.startpc = fn.fn
在 gostartcallfn 中:
// adjust Gobuf as if it executed a call to fn with context ctxt
// and then did an immediate gosave.
func gostartcall(buf *gobuf, fn, ctxt unsafe.Pointer) {
sp := buf.sp
if sys.RegSize > sys.PtrSize {
sp -= sys.PtrSize
*(*uintptr)(unsafe.Pointer(sp)) = 0
}
sp -= sys.PtrSize
*(*uintptr)(unsafe.Pointer(sp)) = buf.pc // 将 goexit 函数调整为当前栈帧的返回地址
buf.sp = sp
buf.pc = uintptr(fn) // 将 PC 设置为 fn
buf.ctxt = ctxt
}
所以当每个 goroutine 结束的时候,都会调用 goexit:
// goexit continuation on g0.
func goexit0(gp *g) {
_g_ := getg() // g0
casgstatus(gp, _Grunning, _Gdead)
if isSystemGoroutine(gp, false) {
atomic.Xadd(&sched.ngsys, -1)
}
gp.m = nil
locked := gp.lockedm != 0
gp.lockedm = 0
_g_.m.lockedg = 0
gp.paniconfault = false
gp._defer = nil // should be true already but just in case.
gp._panic = nil // non-nil for Goexit during panic. points at stack-allocated data.
gp.writebuf = nil
gp.waitreason = 0
gp.param = nil
gp.labels = nil
gp.timer = nil
if gcBlackenEnabled != 0 && gp.gcAssistBytes > 0 {
// 如果 gp 参与了标记
// Flush assist credit to the global pool. This gives
// better information to pacing if the application is
// rapidly creating an exiting goroutines.
scanCredit := int64(gcController.assistWorkPerByte * float64(gp.gcAssistBytes))
atomic.Xaddint64(&gcController.bgScanCredit, scanCredit)
gp.gcAssistBytes = 0
}
// Note that gp's stack scan is now "valid" because it has no
// stack.
gp.gcscanvalid = true
dropg() // 将 g0 与 m 解绑
if GOARCH == "wasm" { // no threads yet on wasm
gfput(_g_.m.p.ptr(), gp)
schedule() // never returns
}
if _g_.m.lockedInt != 0 {
print("invalid m->lockedInt = ", _g_.m.lockedInt, "\n")
throw("internal lockOSThread error")
}
gfput(_g_.m.p.ptr(), gp) // 放回 p.gFree,如果 p.gFree 达到 64 个,则搬移一半到 sched.gFree
if locked {
// The goroutine may have locked this thread because
// it put it in an unusual kernel state. Kill it
// rather than returning it to the thread pool.
// Return to mstart, which will release the P and exit
// the thread.
if GOOS != "plan9" { // See golang.org/issue/22227.
gogo(&_g_.m.g0.sched)
} else {
// Clear lockedExt on plan9 since we may end up re-using
// this thread.
_g_.m.lockedExt = 0
}
}
schedule()
}
go 程序的启动
启动流程大致如下:

P 的数量默认为 CPU 的核心数,M 的数量一开始是1,即只有 m0,后续会根据需要创建。
M 是通过allocm(_p_ *p, fn func())创建的,但只是分配了对应结构体的内存,并没有真正创建操作系统线程。真正创建操作系统线程是在newm(fn func(), _p_ *p)。
什么情况下会调用newm(fn func(), _p_ *p)创建操作系统线程?主要有如下2中情况:
- 创建运行时所需的操作系统线程:sysmon 和 templateThread
- 有空闲的 P 和等待运行的 G,并且没有空闲的 M,此时会创建新的操作系统线程来绑定 P 后执行 G

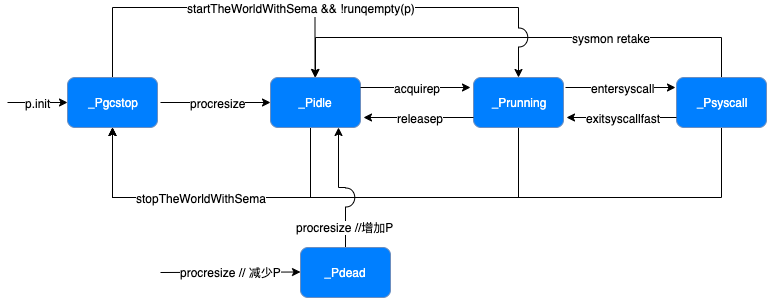
P 的状态转换
procresize(nproc int32) 只在 schedinit() 和 startTheWorldWithSema(emitTraceEvent bool) 中调用
G 的状态转换
(_Gscan)表示能与 GC 标记共存的状态。
