Code For Colorful Life
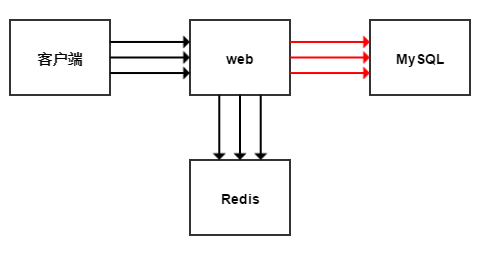
MySQL ibdata 存储空间的回收
前言
在MySQL <= 5.6.5,innodb_file_per_table默认为0,即InnoDB表的数据都会存储在共享表空间ibdata中,除此之外ibdata还存储着数据字典、双写缓冲区、undo log等。
当innodb_file_per_table为0时,ibdata会不断增大,有时会导致磁盘空间不足。通常是InnoDB表的数据导致的,undo log是次要原因。 因为undo log的增加通常是在事务较为繁忙的时候,且事务中做了大量的更新操作,但是undo log占用的空间却可以被重用。InnoDB的purge线程就是负责清理不需要的undo log空间以供其他的undo log使用。
那么为何InnoDB表的数据会成为ibdata增大的主要原因?因为InnoDB表的数据被delete之后的空间是无法被InnoDB重用的,需要人为干预处理= =
Read more...
Storm Trident 学习
Storm支持的三种语义:
- 至少一次
- 至多一次
- 有且仅有一次
至少一次语义的Topology写法
参考资料:Storm消息的可靠性保障 Storm提供了Acker的机制来保证数据至少被处理一次,是由编程人员决定是否使用这一特性,要使用这一特性需要:
- 在Spout emit时添加一个MsgID,那么ack和fail方法将会被调用当Tuple被正确地处理了或发生了错误。
_collector.emit(new Values("field1", "field2", 3) , msgId); - 在Bolt emit时进行锚定。
_collector.emit(tuple, new Values(word));
Read more...
多表数据分页方案
通常情况下,只需要对单表的数据进行分页:
SELECT …… LIMIT ($CURRENT_PAGE - 1) * $PAGE_SIZE, $PAGE_SIZE ORDER BY ……
然而,在比较复杂的业务场景下,数据来自多张表(并非水平分割的表),这时就要考虑多张表的情况下,数据聚合到一起后如何分页了。
这里给出一个参考方案:
假设数据来自A、B表,分页规则按照记录的创建时间排序,再定义一个分页的状态变量time(记录时间):
- 当获取第1页数据时:
SELECT …… FROM A WHERE …… LIMIT 0, $PAGE_SIZE ORDER BY ……和SELECT …… FROM B WHERE …… LIMIT 0, $PAGE_SIZE ORDER BY ……,将这两份数据在代码层面合并到一起后取出前$PAGE_SIZE条记录items,并且记下第$PAGE_SIZE条记录的创建时间为time,再记下items中最后一条A记录的id为aid和最后一个B记录的id为bid; - 当获取第2页数据时:
SELECT …… FROM A WHERE …… AND created <= time AND id != aid LIMIT $PAGE_SIZE * 1, $PAGE_SIZE ORDER BY ……和SELECT …… FROM B WHERE …… AND created <= time AND id != bid LIMIT $PAGE_SIZE * 1, $PAGE_SIZE ORDER BY ……,将这两份数据在代码层面合并到一起后取出前$PAGE_SIZE条记录items,同时更新aid和bid。 - 之后数据的获取以此类推。
之所以记录aid和bid是考虑到同一张表里可能有created相同的记录,并且处于分页的边缘。
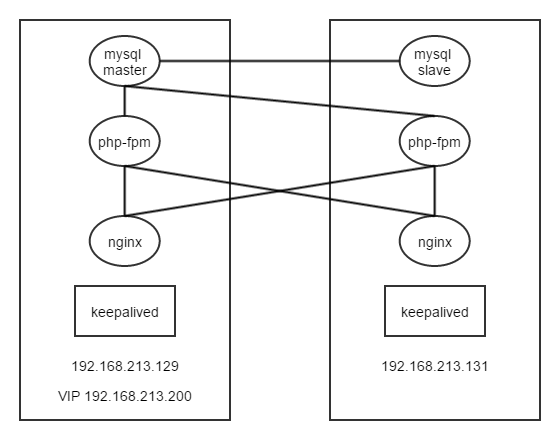
MySQL 主从复制添加slave
在已有的MySQL主从复制下添加slave的方法:
方法一:
1、在已有的slave上,执行stop slave io_thread;,等待Slave_open_temp_tables为0时,执行stop slave sql_thread;
2、然后执行flush tables with read lock;和flush logs;
3、拷贝整个datadir(bin-log、relay-log等信息也要在这里面)内容到new-slave的datadir下;
4、在new-slave上启动mysql后执行start slave;即可。
Read more...
nginx rewrite
参考ngx_http_rewrite_module,对各种rewrite情况进行了实验,总结一下。
rewrite、location、if的context如下:
- rewrite:server、location、if
- location:server、location
- if:server、location
location匹配规则:
- =:完整的字符串匹配
- ~:大小写敏感的正则匹配
- ~*:大小写不敏感的正则匹配
- ^~:如果最长的前缀匹配有这个修饰符,那么将不再检查正则表达式匹配
location匹配顺序:
- 检查前缀匹配,记录下最长前缀匹配,如果有^~修饰符,则停止搜索;
- 检查正则匹配,第一个匹配到正则后停止搜索,如果没有任何正则匹配,那么将使用步骤1中记录的最长前缀。
Read more...