MySQL Index学习
学习自《高性能MySQL 第三版》和网络资源
索引是存储引擎用于快速找到记录的一种数据结构。
在MySQL中,索引是在存储引擎层而不是服务器层实现的。因此,不同存储引擎的索引的工作方式不一样,所支持的索引类型也不同。
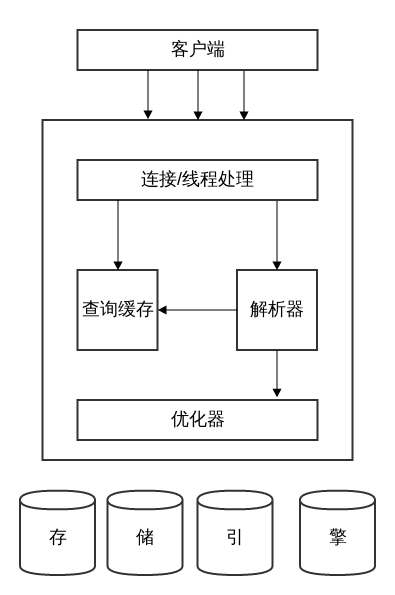
以上的英文说明了MySQL索引大多使用B-Tree(有时候许多人误读为“B减树”,其实是“B(横)杆树”)。实际的存储引擎使用的是B-Tree的变种,例如InnoDB使用的是B+Tree。
为何使用B-Tree作为索引数据结构,网上很多博文都有解释了,主要是与磁盘读取数据方式有关。因为局部性原理认为,通常一个数据被用到,其附近的数据也会立马被用到。
B-Tree索引对如下的类型有效:
- 全值匹配
- 匹配最左前缀
- 匹配列前缀
- 匹配范围值
- 精确匹配某一列并范围匹配另外一列
- 只访问索引的查询
B-Tree索引的限制:
- 如果不按照索引的最左列开始查找,则无法发挥索引的作用。
- 不能跳过索引中的列。
- 如果查询中有某个列的范围查询,则其右边所有列都无法使用索引优化查找。
当然还有其他类型的索引,这里只记录学习InnoDB的索引。
非聚簇索引
单列索引
假设id 字段建立了索引
错误的查询方法:SELECT ... WHERE id + 1 =5
正确的查询方法:SELECT ... WHERE id = 4
假设 date_col 字段建立了索引
错误的查询方法:SELECT ... WHERE TO_DAYS(CURRENT_DATE) - TO_DAYS(date_col) <= 10
正确的查询方法:SELECT ... WHERE date_col <= 计算出来的日期
上面例子中错误的写法主要是因为无法使用到索引,通常,在SQL语句中也因尽量减少函数的调用。
联合索引
在多个列上建立一个索引,例如:CREATE TABLE test(a INT, b INT, c INT, KEY(a, b, c))。
根据B-Tree的限制,有以下查询,引用自mysql 联合索引详解:
-
优:
select * from test where a=10 and b>50 - 优:
select * from test order by a - 差:
select * from test order by b -
差:
select * from test order by c - 优:
select * from test where a=10 order by a - 优:
select * from test where a=10 order by b -
差:
select * from test where a=10 order by c - 优:
select * from test where a>10 order by a - 差:
select * from test where a>10 order by b -
差:
select * from test where a>10 order by c - 优:
select * from test where a=10 and b=10 order by a - 优:
select * from test where a=10 and b=10 order by b -
优:
select * from test where a=10 and b=10 order by c - 优:
select * from test where a=10 and b=10 order by a - 优:
select * from test where a=10 and b>10 order by b - 差:
select * from test where a=10 and b>10 order by c
选择合适的索引列顺序一般经验:将选择性高的列放到索引的最前列,选择性的计算看下文。
前缀索引
对于列的值较长,比如BLOB、TEXT、VARCHAR,就必须建立前缀索引,即将值的前一部分作为索引。这样既可以节约空间,又可以提高查询效率。
那么这就存在一个选择多长的前缀作为索引合适的问题?
索引的选择性:不重复的索引值和数据表的记录总数的比值,该值越高则查询效率越高。因为选择性高的索引可以让MySQL在查找时过滤更多的行,唯一索引的选择性是1。
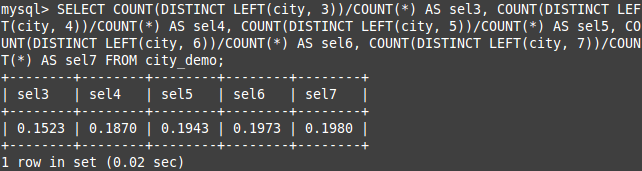
前缀的选择性:不重复的列前缀值和数据表的记录总数的比值,其实和索引的选择性是同一个值来的。
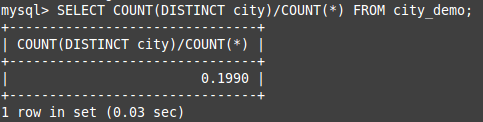
完整列的选择性:不重复的列值和数据表的记录总数的比值。
那么,好的前缀索引就是要让前缀的选择性,接近于完整列的选择性。
例如:
完整列的选择性:
前缀的选择性:
前缀索引优点:能使索引更小,更快的有效方法;缺点:MySQL无法使用前缀索引做 ORDER BY 和 GROUP BY,也无法使用前缀索引做覆盖扫描。
MySQL并不支持后缀索引,但是可以把字符串翻转后存储,并基于此建立前缀索引。
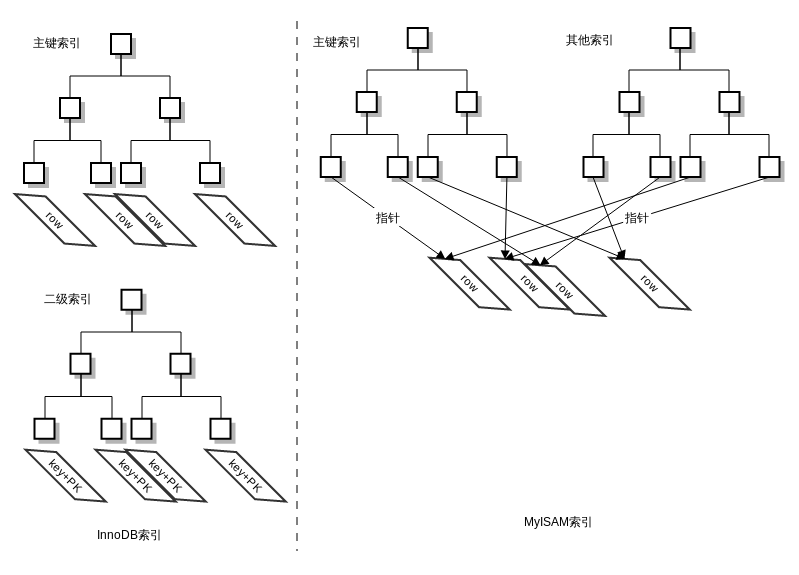
聚簇索引
并不是一种单独的索引类型,而且是一种数据存储方式。
当表有聚簇索引时,它的数据行实际上存放在索引的叶子页中,且一个表只能有一个聚簇索引。
InnoDB默认对主键建立聚簇索引。如果没有定义主键,InnoDB会选择一个具有唯一且非空值的索引来代替。如果没有这样的索引,InnoDB会定义一个隐藏的主键,然后对其建立聚簇索引。一般来说,DBMS都会以聚簇索引的形式来存储实际的数据,它是其它二级索引的基础。二级索引叶子节点保存的不是指向行的物理位置的指针,而是行的主键值。
对于 MyISAM,索引叶子节点上的 data ,并不是数据本身,而是数据存放的物理位置的指针。主索引和辅助索引没啥区别,只是主索引中的key一定得是唯一的。MyISAM 的索引都是非聚簇索引。
优点:
- 减少磁盘IO
- 数据访问比非聚簇索引更快
缺点:
- 如果不是按照主键顺序插入数据,那么插入速度会较慢
- 维护代价高,当然避免非顺序插入,和更新主键的话会好些
一张图了解InnoDB和MyISAM数据存储和索引的区别:
覆盖索引
如果一个索引包含(或者说覆盖)所有要查询的字段的值,则称之为“覆盖索引”。
不是所有类型的索引都可以成为覆盖索引。覆盖索引必须要存储索引列的值,而哈希索引、空间索引和全文索引等都不存储列的值,所以 MySQL 只能使用 B-Tree 索引做覆盖索引。另外不同的存储引擎实现覆盖索引的方式不同,而且不是所有的引擎都支持覆盖索引。